Edits: 2015-01-10 Added another offending character, NO-BREAK SPACE
My recent focus has been loading additional content into SHARE to enrich our offerings, such as TAUG and draft SDTM publications published in 4Q2014. I spent a lot of time having to clean up the obstreperous characters in my Word document sources (i.e., the documents used to render the PDF). I feel compelled to write this short blog entry, hoping it will give you a jump start if you happen to perform similar tasks.
The most significant offenders are the so-called smart quotes. Microsoft Word, as a default, auto-formats straight to curly quotes, meaning it automatically corrects every time you hit the single- or double-quote keys. So, what's wrong with the smart quotes and why am I mucking around with them? First of all, they are not consistently used by our volunteer authors since user can disable the AutoCorrect feature. Second, these character are not ASCII and can only understood by software applications that supports UTF. Until our industry is more acquainted with XML technologies, forcing UTF would introduce unnecessary burden of data transport incompatibilities.
Sidebar
SOA Semantics Manager is a web-based application and supports UTF. For SHARE, we use the default configuration option for character set displays, which is UTF-8. The backend database uses UTF for character encoding.
Hyphens. Apart from the one on the keyboard, four other flavors have been detected, which are not part of ASCII.
Perhaps, the worst kind of obstreperous characters are those non-printerables. You know they are there, but you can't see it. They are hard to detect like household parasites, tagging along in copy-paste buffer.
Below is a table containing a list known offending UTF characters, with replacement values we perform in SHARE.
| Character Image | Unicode Name (Code Point) | Replacement ASCII Character (Decimal) | Remarks |
|---|---|---|---|
 | LEFT SINGLE QUOTATION MARK (U+2018) | ' (39) |
|
 | RIGHT SINGLE QUOTATION MARK (U+2019) | ' (39) |
|
 | LEFT DOUBLE QUOTATION MARK (U+201D) | " (34) |
|
 | RIGHT DOUBLE QUOTATION MARK (U+201D) | " (34) |
|
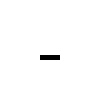 | NON-BREAKING HYPHEN (U+2011) | - (45) | |
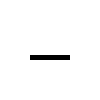 | FIGURE DASH (U+2012) | - (45) |
|
 | EN DASH (U+2013) | - (45) |
|
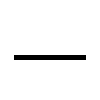 | EM DASH (U+2014) | - (45) |
|
 | HORIZONTAL ELLIPSIS (U+2026) | ... (46, 3 times) |
|
 | ZERO WIDTH SPACE (U+200B) | null (0) |
An example with text:
|
 | NO-BREAK SPACE (U+00A0) | whitespace (32) |
An example with text:
|




Image credit: FileFormat.info
Lastly, here is a snippet of Perl code that implements the above table:
Transform Unicode
sub transformUnicode{
my @input = @_;
for (@input){
s/\x{2018}/'/g; s/\x{2019}/'/g; # left and right curly single-quote
s/\x{201c}/"/g; s/\x{201d}/"/g; # left and right curly double-quote
# all kinds of hyphens/dashes
s/\x{2011}/-/g; # Non-breaking hyphen
s/\x{2012}/-/g; # Figure dash
s/\x{2013}/-/g; # En dash
s/\x{2014}/-/g; # Em dash
s/\x{2026}/.../g; # Horizontal ellipse
# all kinds of spaces
s/\x{00a0}/ /g; # No-break space, a.k.a. Microsoft Word's nonbreaking break
s/\x{200b}//g; # Zero width space, a.k.a. Microsoft Word's optional break
}
return wantarray ? @input : $input[0];
}
Overview
Content Tools