Blog from January, 2015
search
attachments
weblink
advanced
Overview
Content Tools
Introduction
CDISC Controlled Terminology (CT) maintains a codelist of units of measurement (codelist code C71620, short name UNIT). It is used to represent values for unit variables in various domains, such as demographics (AGEU), concomitant medications (CMDOSU), lab (LBORRESU, LBSTRESU), vital signs (VSORRESU, VSSTRESU). Note: AGEU is a codelist subset of the UNIT superset.
Indiana University School of Medicine's Regenstrief Institute develops the Unified Code for Units of Measure (UCUM). It is a code system of units intended to be unambiguous to both human and machine. It has many applications in life sciences, such as EHR, and, EDI and HL7 electronic messaging. Logical Observation Identifiers Names and Codes (LOINC) is another code system that incorporates UCUM.
Even though many terms are identical between CDISC and UCUM, there are differences. For example, millimeter of mercury, a unit commonly used to measure blood pressure, is mmHg in CDISC, while mm[Hg] in UCUM. Here are a few examples showing differing values:
| Table 1: CDISC CT vs. UCUM | ||
| Long Label | CDISC CT | UCUM |
|---|---|---|
| Cells per Microliter | cells/uL | {Cells}/uL |
| Hour | HOURS | h |
| Joule | Joule | J |
| Millimeter of Mercury | mmHg | mm[Hg] |
| Millisecond | msec | ms |
| Pound | LB | [lb_av] |
| Tablet Dosing Unit | TABLET | {tbl} |
Therefore, a mapping between the two codelists is helpful for any two heterogeneous systems to be interoperable and be successful at exchanging data.
NCI EVS Resources
CDISC and NCI EVS have long been partners at curating and registering CDISC controlled terminologies in the NCI Thesaurus (NCIt), hence the NCI Metathesaurus (NCIm). As a matter of fact, a careful examination into NCIm reveals the relationship between CDISC and UCUM exists. A search of the term millimeter of mercury shows the evidence (source: http://1.usa.gov/1zoRA96):

At this point, we gather these about the NCI EVS:
- All CDISC CT can be retrieved from the NCIt browser
- NCIt contains biomedical knowledge from multiple sources, e.g., CDISC, UCUM, SNOMED, etc.
- Relationships between sources are maintained, where applicable
Thesaurus OWL/RDF
Despite being off to a good start, manual lookup via the NCIt browser would be too tedious to be useful. Upon further research, NCI Center for Biomedical Informatics and Information Technology (CBIIT) publishes the NCIt in OWL/RDF format in a regular basis.
With an OWL/RDF file at our disposal, SPARQL is the tool to do some graph-based data analyses.
The following is a snippet from the Thesaurus OWL/RDF file, showing how it represents metadata for the term millimeter of mercury:
Millimeter of Mercury from Thesaurus.OWL
<!-- http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl#Millimeter_of_Mercury -->
<owl:Class rdf:about="#C49670">
<rdfs:label rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Millimeter of Mercury</rdfs:label>
<rdfs:subClassOf rdf:resource="#C67332"/>
<P97 rdf:parseType="Literal"><ncicp:ComplexDefinition><ncicp:def-definition>A non-SI unit of pressure equal to 133,332 Pa or 1.316E10-3 standard atmosphere. Use of this unit is generally deprecated by ISO and IUPAC.</ncicp:def-definition><ncicp:def-source>NCI</ncicp:def-source></ncicp:ComplexDefinition></P97>
<P325 rdf:parseType="Literal"><ncicp:ComplexDefinition><ncicp:def-definition>A unit of pressure equal to 0.001316 atmosphere and equal to the pressure indicated by one millimeter rise of mercury in a barometer at the Earth's surface. (NCI)</ncicp:def-definition><ncicp:def-source>CDISC</ncicp:def-source></ncicp:ComplexDefinition></P325>
<P90 rdf:parseType="Literal"><ncicp:ComplexTerm><ncicp:term-name>mm[Hg]</ncicp:term-name><ncicp:term-group>AB</ncicp:term-group><ncicp:term-source>UCUM</ncicp:term-source></ncicp:ComplexTerm></P90>
<code rdf:datatype="http://www.w3.org/2001/XMLSchema#string">C49670</code>
<P108 rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Millimeter of Mercury</P108>
<A8 rdf:resource="http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl#C71620"/>
</owl:Class>
To de-reference the pseudo-properties P90 (Synonym with Source Data) and P108 (Preferred Name) above:
An explanation for the above OWL snippet:
- Line #3 is the beginning of the owl:Class C49670, which, by no accident, is the c-code for millimeter of mercury we are accustomed to seeing on the CDISC CT spreadsheet.
- On line #11, it shows C49670 is associated to another class C71620, which is the UNIT codelist itself.
- On line #9, it contains the c-code as a property.
- On line #10, it contains the NCI preferred name of C49670.
- On line #8, it contains the UCUM mapping. Note that the value AB in the XML tag ncicp:term-group signifies the entry is about unit symbols used by UCUM. Other values may appear, but do not relate to this demonstration.
- Lines #6-7 contain definitions of the class.
- Lines #15-41 contain definitions of the pseudo-properties P90 and P108 for easy reference. There are many other pseudo-objects in the Thesaurus OWL/RDF files.
With the above sample depicting the model, the following is a SPARQL query for obtaining a list objects having a UCUM mapping:
SPARQL for Extracting UCUM Mappings
PREFIX nci: <http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl#>
SELECT ?conceptCode ?preferredName (STRAFTER(STRBEFORE(STR(?synonym), "</ncicp:term-name>"), "<ncicp:term-name>") as ?ucum)
FROM <http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl>
WHERE {
?class a owl:Class ;
nci:code ?conceptCode ;
nci:P108 ?preferredName ;
nci:P90 ?synonym .
FILTER(STRAFTER(STRBEFORE(STR(?synonym), "</ncicp:term-source>"), "<ncicp:term-source>") = "UCUM")
FILTER(STRAFTER(STRBEFORE(STR(?synonym), "</ncicp:term-group>"), "<ncicp:term-group>") = "AB")
}
A sample output matching the terms shown in Table 1 above:
| Table 2: Partial results from extracting metadata in Thesaurus OWL/RDF using SPARQL | ||
| conceptCode | preferredName | ucum |
|---|---|---|
| C67242 | Cells per Microliter | {Cells}/uL |
| C25529 | Hour | h |
| C42548 | Joule | J |
| C49670 | Millimeter of Mercury | mm[Hg] |
| C41140 | Millisecond | ms |
| C48531 | Pound | [lb_av] |
| C48542 | Tablet Dosing Unit | {tbl} |
CDISC CT OWL/RDF
Incidentally, all CDISC CT packages are also available in OWL/RDF. The goal is to reduce the UCUM query above to only the entries found on the UNIT (C71620) codelist. Continuing with the flow, this is a snippet from the CDISC CT OWL/RDF for the same term, millimeter of mercury:
Millimeter of Mercury from sdtm-terminology.owl
<CodeList OID="CL.C71620.UNIT" Name="Unit" DataType="text" nciodm:ExtCodeID="C71620" nciodm:CodeListExtensible="Yes">
<Description>
<TranslatedText xml:lang="en">Terminology codelist used for units within CDISC.</TranslatedText>
</Description>
<EnumeratedItem CodedValue="mmHg" nciodm:ExtCodeID="C49670">
<nciodm:CDISCSynonym>Millimeter of Mercury</nciodm:CDISCSynonym>
<nciodm:CDISCDefinition>A unit of pressure equal to 0.001316 atmosphere and equal to the pressure indicated by one millimeter rise of mercury in a barometer at the Earth's surface. (NCI)</nciodm:CDISCDefinition>
<nciodm:PreferredTerm>Millimeter of Mercury</nciodm:PreferredTerm>
</EnumeratedItem>
<nciodm:CDISCSubmissionValue>UNIT</nciodm:CDISCSubmissionValue>
<nciodm:CDISCSynonym>Unit</nciodm:CDISCSynonym>
<nciodm:PreferredTerm>CDISC SDTM Unit of Measure Terminology</nciodm:PreferredTerm>
</CodeList>
Unlike the esoteric nature in the Thesaurus OWL/RDF, the CDISC CT one is very straightforward and readable. With that, here is a SPARQL query to extract information such as submission values and their c-code from the UNIT codelist:
SPARQL for Extracting UCUM Mappings
PREFIX mms: <http://rdf.cdisc.org/mms#>
PREFIX cts: <http://rdf.cdisc.org/ct/schema#>
SELECT ?conceptCode ?cdiscSubmissionVal
FROM <http://rdf.cdisc.org/ct/schema>
FROM <http://rdf.cdisc.org/mms>
FROM <http://rdf.cdisc.org/sdtm-terminology>
WHERE {
?pv a mms:PermissibleValue ;
cts:nciCode ?conceptCode ;
cts:cdiscSubmissionValue ?cdiscSubmissionVal ;
mms:inValueDomain ?clCcode .
{
?clCcode cts:codelistName ?clName ;
cts:nciCode "C71620" ;
}
}
A sample output matching the terms shown in Tables 1 and 2 above:
| Table 3: Partial results from extracting metadata in CDISC OWL/RDF using SPARQL | |
| conceptCode | cdiscSubmissionVal |
|---|---|
| C67242 | cells/uL |
| C25529 | HOURS |
| C42548 | Joule |
| C48531 | LB |
| C49670 | mmHg |
| C41140 | msec |
| C48542 | TABLET |
Final Query and Output
The two result sets can be linked via the individual term's c-code. Therefore, the final query is a combination of the two SPARQL queries above, with a slight adjustment to make the nested queries work efficiently. It yields 143 mappings for 130 unique terms.
- cdisc_ct_ucum.rq - Final SPARQL text that extract UCUM information from Thesaurus and subset it to the UNIT codelist in CDISC CT
- cdisc_ct_ucum.txt - Result set in tab-delimited format
Conclusion
NCI EVS actively maintains a rich repository of terminology and biomedical ontology. Their OWL/RDF offering enables scalable IT solutions to search, link, and combine intricate biomedical concepts. This demonstration illustrates one semantic web technology application. SPARQL made analyzing over 2,160,000 triples (2,100,000 from Thesaurus, 60,000 from CDISC CT for SDTM) with ease. The more UCUM entries curated by NCI EVS, the more mappings will become available.
End Notes
- SPARQL as specified by W3C: http://www.w3.org/2009/sparql/wiki/Main_Page
- All SPARQL queries and OWL/RDF files were processed using TopQuadrant TopBraid Composer FE Version 4.4.0.
- These file versions are used in this demonstration: NCI Thesaurus 14.10d; and, CDISC CT 2014-09-26
- URL to download NCI Thesaurus OWL/RDF: http://cbiit.nci.nih.gov/evs-download/thesaurus-downloads
- URL to download CDISC CT OWL/RDF for SDTM: http://evs.nci.nih.gov/ftp1/CDISC/SDTM/SDTM%20Terminology.OWL.zip
Edits: 2015-01-10 Added another offending character, NO-BREAK SPACE
My recent focus has been loading additional content into SHARE to enrich our offerings, such as TAUG and draft SDTM publications published in 4Q2014. I spent a lot of time having to clean up the obstreperous characters in my Word document sources (i.e., the documents used to render the PDF). I feel compelled to write this short blog entry, hoping it will give you a jump start if you happen to perform similar tasks.
The most significant offenders are the so-called smart quotes. Microsoft Word, as a default, auto-formats straight to curly quotes, meaning it automatically corrects every time you hit the single- or double-quote keys. So, what's wrong with the smart quotes and why am I mucking around with them? First of all, they are not consistently used by our volunteer authors since user can disable the AutoCorrect feature. Second, these character are not ASCII and can only understood by software applications that supports UTF. Until our industry is more acquainted with XML technologies, forcing UTF would introduce unnecessary burden of data transport incompatibilities.
Sidebar
SOA Semantics Manager is a web-based application and supports UTF. For SHARE, we use the default configuration option for character set displays, which is UTF-8. The backend database uses UTF for character encoding.
Hyphens. Apart from the one on the keyboard, four other flavors have been detected, which are not part of ASCII.
Perhaps, the worst kind of obstreperous characters are those non-printerables. You know they are there, but you can't see it. They are hard to detect like household parasites, tagging along in copy-paste buffer.
Below is a table containing a list known offending UTF characters, with replacement values we perform in SHARE.
| Character Image | Unicode Name (Code Point) | Replacement ASCII Character (Decimal) | Remarks |
|---|---|---|---|
 | LEFT SINGLE QUOTATION MARK (U+2018) | ' (39) |
|
 | RIGHT SINGLE QUOTATION MARK (U+2019) | ' (39) |
|
 | LEFT DOUBLE QUOTATION MARK (U+201D) | " (34) |
|
 | RIGHT DOUBLE QUOTATION MARK (U+201D) | " (34) |
|
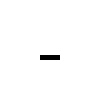 | NON-BREAKING HYPHEN (U+2011) | - (45) | |
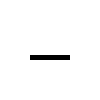 | FIGURE DASH (U+2012) | - (45) |
|
 | EN DASH (U+2013) | - (45) |
|
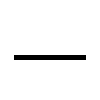 | EM DASH (U+2014) | - (45) |
|
 | HORIZONTAL ELLIPSIS (U+2026) | ... (46, 3 times) |
|
 | ZERO WIDTH SPACE (U+200B) | null (0) |
An example with text:
|
 | NO-BREAK SPACE (U+00A0) | whitespace (32) |
An example with text:
|




Image credit: FileFormat.info
Lastly, here is a snippet of Perl code that implements the above table:
Transform Unicode
sub transformUnicode{
my @input = @_;
for (@input){
s/\x{2018}/'/g; s/\x{2019}/'/g; # left and right curly single-quote
s/\x{201c}/"/g; s/\x{201d}/"/g; # left and right curly double-quote
# all kinds of hyphens/dashes
s/\x{2011}/-/g; # Non-breaking hyphen
s/\x{2012}/-/g; # Figure dash
s/\x{2013}/-/g; # En dash
s/\x{2014}/-/g; # Em dash
s/\x{2026}/.../g; # Horizontal ellipse
# all kinds of spaces
s/\x{00a0}/ /g; # No-break space, a.k.a. Microsoft Word's nonbreaking break
s/\x{200b}//g; # Zero width space, a.k.a. Microsoft Word's optional break
}
return wantarray ? @input : $input[0];
}