Blog
search
attachments
weblink
advanced
Overview
Content Tools
Disclaimer
The views and opinions expressed in this blog entry are those of mine and do not reflect the official policy or position of CDISC.
I am learning about natural language processing (NLP) as part of my self-teaching journey in Data Science.
My set up is simple. Python and an NLP package. scispaCy is an open-source library for processing biomedical text. [1] It works with multiple pre-trained models, such as the The BioCreative V Chemical Disease Relation (BC5CDR) corpus for biomedical terms. [2] BioNLP13CG corpus is another example, which is a model for cancer genetics.
As a test run, I selected a small paragraph from the work-in-progress COVID-19 Interim User Guide. [3] This is a text about a data collection example for the disease's signs and symptoms:
Data collection may include questions about groups of symptoms, such as
- GI symptoms (nausea, vomiting, diarrhea)
- Cough (non-productive, productive, or haemoptisis)
The next step was to extract named entities by running the signs and symptoms text through the BC5CDR biomedical model, A named entity is text with a label of name of things. For BC5CDR, the entity types are DISEASE and CHEMICAL. This process is often referred to as named entity recognition (NER). These are the results:
| Entity | Entity Type |
|---|---|
| nausea | DISEASE |
| vomiting | DISEASE |
| diarrhea | DISEASE |
| Cough | DISEASE |
| haemoptisis | DISEASE |
The first surprise was a programmatic method to link discovered entity with Unified Medical Language System (UMLS). UMLS is maintained by U.S. National Library of Medicine (NLM). This is appealing, when a term or concept is curated in the UMLS, a formal definition exists. Each concept in the UMLS has a Concept Unique Identifier (CUI). [4] This process is typically called named entity linking (NEL).
Let's take a look at the outcome, with green shaded rows indicating my preferred match:
| Entity | CUI | Name | Definition | Score |
|---|---|---|---|---|
| nausea | C0027497 | Nausea | An unpleasant sensation in the stomach usually accompanied by the urge to vomit. Common causes are early pregnancy, sea and motion sickness, emotional stress, intense pain, food poisoning, and various enteroviruses. | 1.0 |
| nausea | C4085862 | Bothered by Nausea | A question about whether an individual is or was bothered by nausea. | 1.0 |
| nausea | C4255480 | Nausea:Presence or Threshold:Point in time:^Patient:Ordinal | None | 1.0 |
| nausea | C4084796 | How Often Nausea | A question about how often an individual has or had nausea. | 1.0 |
| nausea | C1963179 | Nausea Adverse Event | None | 1.0 |
| vomiting | C0042963 | Vomiting | The forcible expulsion of the contents of the STOMACH through the MOUTH. | 1.0 |
| vomiting | C4084767 | Bothered by Vomiting | A question about whether an individual is or was bothered by vomiting. | 0.9999999403953552 |
| vomiting | C4084768 | Usual Severity Vomiting | A question about the usual severity of an individual's vomiting. | 0.9999999403953552 |
| vomiting | C1963281 | Vomiting Adverse Event | None | 0.9999999403953552 |
| vomiting | C4084766 | How Much Distress Vomiting | A question about an individual's distress from their vomiting. | 0.9999999403953552 |
| diarrhea | C0011991 | Diarrhea | An increased liquidity or decreased consistency of FECES, such as running stool. Fecal consistency is related to the ratio of water-holding capacity of insoluble solids to total water, rather than the amount of water present. Diarrhea is not hyperdefecation or increased fecal weight. | 1.0 |
| diarrhea | C4084784 | How Much Distress Diarrhea | A question about an individual's distress from their diarrhea. | 1.0 |
| diarrhea | C4084802 | Usual Severity Diarrhea | A question about the usual severity of an individual's diarrhea. | 1.0 |
| diarrhea | C1963091 | Diarrhea Adverse Event | None | 1.0 |
| diarrhea | C3641756 | Have Diarrhea | A question about whether an individual has or had diarrhea. | 1.0 |
| Cough | C0010200 | Coughing | A sudden, audible expulsion of air from the lungs through a partially closed glottis, preceded by inhalation. It is a protective response that serves to clear the trachea, bronchi, and/or lungs of irritants and secretions, or to prevent aspiration of foreign materials into the lungs. | 1.0 |
| Cough | C1961131 | Cough Adverse Event | None | 1.0 |
| Cough | C3274924 | Have Been Coughing | A question about whether an individual is or has been coughing. | 1.0 |
| Cough | C3815497 | Cough (guaifenesin) | None | 1.0 |
| Cough | C4084725 | Usual Severity Cough | A question about the usual severity of an individual's cough. | 1.0 |
| haemoptisis | None returned | |||
Notice how the table above does not include any UMLS concept for the named entity haemoptisis. With some online searches, it came to me as another surprise that it is due to a typographical error. After correcting it to "hemoptysis," a hit appears in the outcome, as follows:
| Entity | CUI | Name | Dfinition | Score |
|---|---|---|---|---|
| hemoptysis | C0019079 | Hemoptysis | Expectoration or spitting of blood originating from any part of the RESPIRATORY TRACT, usually from hemorrhage in the lung parenchyma (PULMONARY ALVEOLI) and the BRONCHIAL ARTERIES. | 1.0 |
| hemoptysis | C0030424 | Paragonimiasis | Infection with TREMATODA of the genus PARAGONIMUS. | 0.7546218633651733 |
Suffice to mention, these CUIs are available on the NCI Metathesaurus. This is the URL template: https://ncim.nci.nih.gov/ncimbrowser/ConceptReport.jsp?dictionary=NCI%20Metathesaurus&code={CUI}
Visualization
spaCy includes built in visualization constructors to display part-of-speech tags and syntactic dependencies. The following graphic is the rendition using the text described above:

We discussed named entity recognition, which can be displayed as such:

Example Code
import scispacy
import spacy
from scispacy.umls_linking import UmlsEntityLinker
from spacy import displacy
nlp = spacy.load("en_ner_bc5cdr_md")
linker = UmlsEntityLinker(resolve_abbreviations=True)
nlp.add_pipe(linker)
text = """
Data collection may include questions about groups of symptoms, such as
GI symptoms (nausea, vomiting, diarrhea)
Cough (non-productive, productive, or haemoptisis)
"""
doc = nlp(text)
entities = doc.ents
for entity in entities:
print(entity.text, entity.start_char, entity.end_char, entity.label_)
for umls_ent in entity._.umls_ents:
# tuple with 2 values
conceptId, score = umls_ent
print(f"Name: {entity}")
print(f"CUI: {conceptId}, Score {score}")
print(linker.umls.cui_to_entity[umls_ent[0]])
print()
colors = {
'CHEMICAL': 'lightpink',
'DISEASE': 'lightorange',
}
# show NER
displacy.serve(doc, style="ent", host="127.0.0.1", options={'colors': colors})
displacy.serve(doc, style="dep", host="127.0.0.1")
The Road Ahead
At this point, there seems to be a lot of NLP opportunities and applications in standards development. Linkage to UMLS will allow team members to ensure semantic meaning by referencing the curated definition. Quality will increase as I demonstrated how detecting the spelling error was an unintended experience. I can certainly see it has a utility in CDISC 360's biomedical concept authoring. Named entities can be used as keywords or tags in Example Collection.
Last Note
I want to share a note on installation. scispacy and spacy require Cython, a C-extension for Python. I spent too many hours in troubleshooting before realizing I had installed a 32-bit port of Python onto a PC with Windows 10 64-bit. This caused many compiler errors because all the Microsoft Visual Studio runtime redistributables and compilers were 64-bit. Installing the 64-bit binaries for Python corrected all the installation issues.
References
[1] scispaCy: https://allenai.github.io/scispacy/
[2] BC5CDR corpus. https://www.ncbi.nlm.nih.gov/research/bionlp/Data/
[3] CDISC Interim User Guide for COVID-19. https://www.cdisc.org/interim-user-guide-covid-19/
[4] Unique Identifiers in the Metathesaurus. https://www.nlm.nih.gov/research/umls/new_users/online_learning/Meta_005.html
Disclaimer
The views and opinions expressed in this blog entry are those of mine and do not reflect the official policy or position of CDISC.
In this blog, I want to highlight one part of a project deliverable from the Controlled Terminology (CT) Relationships subteam - metadata about CDISC CT for the SDTM TS dataset.
Background
Before going into detail, here is a bit about how this Standards Development team was established. The team began at the CDISC Working Group Meeting in 2017 at Silver Spring, Maryland, U.S.A. NCI EVS representatives raised maintenance issues that stemmed from drastically different publication cadence between CDISC CT and Implementation Guide. Volunteers also shared implementation challenges about CDISC CT. After much discussion, the attendees agreed to this general problem statement for a new development subteam to tackle:
Relationships between published terminology codelists and variable metadata are not explicit enough or are incomplete in published Implementation Guides (IG) or Therapeutic Area User Guides (TAUG).
Project Deliverables
Fast forward to today, the team recently finished reviewing all the SDTM v1.4 & SDTMIG v3.2 domain variables. A project deliverable is being compiled with two main components:
- A model for expressing CT relationships for SDTM
- Metadata that details the relationship between variables and CDISC CT codelists & terms, or external dictionaries
Problem Discussions
Of all the SDTM datasets reviewed, I find Trial Summary (TS) the most intriguing due to its complex CT requirements.
The SDTM TS dataset, by definition, is "a trial design domain that contains one record for each trial summary characteristic." [1] A trial summary characteristic is represented by two parts: 1) TSPARM/TSPARMCD pair, or parameter/parameter code, respectively; and, 2) TSVAL, or value. Permissible values for TSVAL are dependent on TSPARM/TSPARMCD. In other words, CT requirement for TSVAL is dependent on TSPARM/TSPARM for any given dataset record.
Here is an excerpt from the SDTMIG v3.2's Appendix C1:
| # | TSPARMCD | TSPARM | TSVAL (Codelist Name or Format) |
|---|---|---|---|
| 1 | ADDON | Added on to Existing Treatments | No Yes Response |
| 2 | TDIGRP | Diagnosis Group | SNOMED CT |
| 3 | PCLAS | Pharmacological Class of Inv Therapy | NDF-RT |
| 4 | TRT | Investigational Therapy or Treatment | UNII |
Let's inspect and discuss each of them.
For #1, although seasoned CDISC users would likely recognize "No Yes Response" as one of the CDISC CT codelists, this notation inadvertently puts naive users at disadvantage. Even to trained users, it does not mean all the terms within that CT codelist are permissible. From a process automation's perspective, it contains no information to a machine about its purpose. Therefore, it isn't ideal for either human-, or machine-readability.
About #2 and #3, SNOMED CT and NDF-RT are external dictionaries. NDF-RT has been renamed to MED-RT. Not all users recognize these external dictionaries, especially when usages could be specific to certain geographical regions. Also, users face this implementation challenge: which component of these external dictionaries do they use to populate TSVAL? Therefore, information published in this SDTMIG appendix is not contemporary and is not explicit.
UNII is a coded identifier for all registered ingredients used in products regulated by US FDA. For example, 362O9ITL9D is the UNII for acetaminophen. In #4, it is misleading to populate TSVAL with UNII. It is more appropriate to populate this coded value in TSVALCD (parameter value code). The decode, so to speak, would instead go to TSVAL. In this instance, TSVAL shall correspond to the preferred substance name, a component in the Global Substance Registration System, which is maintained by U.S. FDA.
Solutions
What extra information is needed to make example #1 more readable to both human and machines? Since it is about CDISC CT, common attributes, such as codelist names (short & long) and c-codes will immediately be helpful. An attribute for subsetting codelist will be necessary to specify permissible values.
About the external dictionaries in examples #2 through #4, extra information to describe them will be elucidating, such as 1) owning organization, 2) dictionary's name, and, 3) dictionary's component.
An extra bit of metadata will be essential to cope with multiple regulatory requirements for SDTM data submissions.
All of the above together formulates the model (or, structure) for complete disambiguation of the relationships between CDISC CT and SDTM variables. The following tables illustrate this model in a tabular manner, along with the example parameters:
For use when CDISC CT is relevant:
| # | Usages | Domain | Variable | Condition 1 | C-Code for Value in Condition 1 | Condition 2 | C-Code for Value in Condition 2 | CDISC CT Codelist Short Name | CDISC CT Codelist C-Code | CDISC CT Codelist Long Name | Permissible Value from CDISC CT | Permissible Value's C-Code | Health Authority Provisions |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Context of which this row of metadata applies; valid values are versioned foundational standards | A domain abbreviation found in foundational standard in "Usages" | A variable name | May be used for normalized datasets such as SuppQual, Findings domains, and TS ** Use this for TESTCD and PARMCD; or, QNAM | Conditional Value's c-code in the Condition column, if applicable | May be used for normalized datasets such as SuppQual, Findings domains, and TS ** Use this for TEST and PARM to pair with TESTCD and PARMCD; otherwise, not needed | Conditional Value's c-code in the Condition column, if applicable | The CDISC CT Codelist that controls the values referenced in "Domain" and "Variable" columns | C-code that pairs with "CDISC CT Codelist Short Name" | Long name that pairs with "CDISC CT Codelist Short Name" | A semi-colon delimited value list subset from the codelist referenced in "CDISC CT Codelist Short Name" | C-codes for each value in "Permissible Value from CDISC CT", also semi-colon delimited | Specify to which health authority this set of metadata is applicable. Leave blank when not applicable. Example: "US FDA", "Japan PMDA" | |
| 1 | SDTMIG v3.2 | TS | TSVAL | TSPARMCD EQ "ADDON" | C49703 | TSPARM EQ "Added on to Existing Treatments" | C49703 | NY | C66742 | No Yes Response | N; Y | C49488; C49487 |
For use when external dictionary is relevant:
| # | Usages | Domain | Variable | Condition 1 | C-Code for Value in Condition 1 | Condition 2 | C-Code for Value in Condition 2 | External Dictionary's Organization | External Dictionary's Name | External Dictionary's Component | Descriptive Information | Health Authority Provisions |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Context of which this row of metadata applies; valid values are versioned foundational standards | A domain abbreviation found in foundational standard in "Usages" | A variable name | May be used for normalized datasets such as SuppQual, Findings domains, and TS ** Use this for TESTCD and PARMCD; or, QNAM | Conditional Value's c-code in the Condition column, if applicable | May be used for normalized datasets such as SuppQual, Findings domains, and TS ** Use this for TEST and PARM to pair with TESTCD and PARMCD; otherwise, not needed | Conditional Value's c-code in the Condition column, if applicable | Used when "Variable" is controlled by an external dictionary. Example: "MSSO", "Regenstrief Institute" | Used when "Variable" is controlled by an external dictionary. Example: "MedDRA", "LOINC" | Used when "Variable" is controlled by an external dictionary. Example: "Preferred Term Code", "LOINC Code" | Additional information that is useful for implementers from a citable source ** Citable implementation information that can't be molded into detail metadata; or, regulatory agency's requirements | Specify to which health authority this set of metadata is applicable. Leave blank when not applicable. Example: "US FDA", "Japan PMDA" | |
| 2 | SDTMIG v3.2 | TS | TSVAL | TSPARMCD EQ "TDIGRP" | C49650 | TSPARM EQ "Diagnosis Group" | C49650 | International Health Terminology Standards Organisation (IHTSDO) | SNOMED CT | SNOMED CT Fully Specified Name | Appendix C of SDTMIG v3.2 specifies SNOMED CT. See FDA TCG section 6.6.1.1 Also see Notes in Appendix C of SDTMIG v3.2: If the study population is healthy subjects (i.e., healthy subjects flag is Y), this parameter is not expected. | US FDA |
| 2 | SDTMIG v3.2 | TS | TSVALCD | TSPARMCD EQ "TDIGRP" | C49650 | TSPARM EQ "Diagnosis Group" | C49650 | International Health Terminology Standards Organisation (IHTSDO) | SNOMED CT | SNOMED CT Identifier (SCTID) | US FDA | |
| 3 | SDTMIG v3.2 | TS | TSVAL | TSPARMCD EQ "PCLAS" | C98768 | TSPARM EQ "Pharmacologic Class" | C98768 | Department of Veterans Affairs/Veterans Health Administration | Medication Reference Terminology (MED-RT) | Established pharmacologic class (EPC) | Note: Refer to citation in FDA TCG guidance. If the established pharmacologic class (EPC) is not available for an active moiety, then the sponsor should discuss the appropriate MOA, PE, and CS terms with the review division. | US FDA; Japan PMDA |
| 3 | SDTMIG v3.2 | TS | TSVALCD | TSPARMCD EQ "PCLAS" | C98768 | TSPARM EQ "Pharmacologic Class" | C98768 | Department of Veterans Affairs/Veterans Health Administration | Medication Reference Terminology (MED-RT) | Alphanumeric unique identifier (NUI) | US FDA; Japan PMDA | |
| 4 | SDTMIG v3.2 | TS | TSVAL | TSPARMCD EQ "TRT" | C41161 | TSPARM EQ "Investigational Therapy or Treatment" | C41161 | U.S. Food and Drug Administration (US FDA) | Global Substance Registration System | Preferred substance name | US FDA; Japan PMDA | |
| 4 | SDTMIG v3.2 | TS | TSVALCD | TSPARMCD EQ "TRT" | C41161 | TSPARM EQ "Investigational Therapy or Treatment" | C41161 | U.S. Food and Drug Administration (US FDA) | Global Substance Registration System | Unique Ingredient Identifier (UNII) | US FDA; Japan PMDA |
Project Status
The project deliverable is currently undergoing Internal Review per CDISC's standard development process. [2] All artifacts created by the team are available on the CDISC Wiki, along with a Read Me section. [3] The team expects Public Review to begin in 3rd quarter of 2020.
Expected Outcomes
The team operates with a tight alignment with CDISC's strategic goal to transform standards and clinical knowledge into a multidimensional representation to support automation. [4] Users can expect the metadata will be accessible via CDISC Library when it completes the development lifecycle. Future IG and TAUG may reference CT Relationships to keep concurrent with CDISC CT publication cadence. The team may incorporate additional kinds of CT relationships metadata, e.g., CT codetables. [5] Also an aspiration, the team, using the same methodology, will expand to cover CDASH, SEND, and ADaM.
Acknowledgements
I want to acknowledge these people for their contributions and domain expertise: Kristin Kelly (Pinnacle 21), Michael Lozano (Eli Lilly), Sharon Weller (Eli Lilly), Donna Sattler (BMS), Debbie O’Neill (Merck), Smitha Karra* (Gilead), Judith Goud (Nurocor), Swarupa Sudini (Pfizer), Anna Pron-Zwick (AstraZeneca), Craig Zwickl (Independent), Erin Muhlbradt* (NCI EVS), Fred Wood (TalentMine), Trish Gleason (BMS), Sharon Hartpence (BMS), Diane Wold (CDISC). Special thanks to Ann White for copyediting.
* denotes team co-lead, current and past
References
[1] CDISC SDTM CT P34. Extracted from CDISC Library Data Standards Browser: https://library.cdisc.org/browser/ct/2018-06-29?products=sdtmct-2018-06-29&codelists=C66734&codevalue=C53483
[2] CDISC Operating Procedure CDISC -COP -001 Standards Development. https://www.cdisc.org/system/files/about/cop/CDISC-COP-001-Standards_Development_2019.pdf
[3] Internal Review package. https://wiki.cdisc.org/display/CT/Internal+Review
[4] CDISC Strategic Plan 2019-2022. https://www.cdisc.org/sites/default/files/resource/CDISC_2019_2022_Strategic_Plan.pdf
[5] CT codetables. https://www.cdisc.org/standards/terminology, expand Codetable Mapping Files
Disclaimer
The views and opinions expressed in this blog entry are those of mine and do not reflect the official policy or position of CDISC.
Mainstream definition for unstructured data is data that do not contain descriptive information about the data themselves. An email body is unstructured. A newspaper op-ed is unstructured; definition further goes to describe structured data to have a rigid schema requirement. Semi-structured data are the middle category, where meaning of data is, for example, self-explanatory using markup tags.
Below are examples to illustrate these three kinds of data.
Example of unstructured data
Taylor was born on March 12th in 2008. Carter was born 10 years and 9 months after Taylor.
Example of semi-structured data
| Name | Birthdate |
|---|---|
| Taylor 🐕 | 3/12/2008 |
| Carter 🐈 | 12/12/2018 |
Example of structured data
Data fitting the schema, in JSON format.
{
"animals": [
{
"name": "Taylor",
"species": "canine",
"birthdate": "3/12/2008",
"dateFormat": "mm/dd/yyyy"
},
{
"name": "Carter",
"species": "feline",
"birthdate": "12/12/2018"
}
]
}
Only with the structured data example would you realize Taylor is about a dog and a cat for Carter. The schema serves an important function: gives context and rules to the data. This schema also contains information about defaults, optionality, and valid values. Because of the schema, machine would be able to process the pet animal data much more efficiently. Predictability is key.
I would like to continue with setting aside the classification of normative versus informative content in a CDISC publication. Two reasons. Firstly, no publications have them clearly delineated. More importantly, the degree of structuredness does not make content any more or less normative.
CDISC publishes foundational standards in PDF. When loading these standards into the metadata repository, with the exception of Controlled Terminology, a good amount of effort is spent to tease out basic metadata from the documents. By basic metadata, I mean those matter most toward process automation such as variable, data set, and class information common in domain specifications.
These basic metadata do not always share identical structure across CDISC products. CDASHIG variable's attributes differ from SDTMIG variable's; different versions of the same CDISC product also do not always fit in one structure. SDTM v1.2 & v1.3 contain flags for variable allowance in human clinical (SDTMIG) or animal toxicology (SEND) data sets. In subsequent SDTM versions, these flags were removed and subsumed by description text; same attributes do not always have the same value domains. Each product has its own set of values for the Core attribute. "HR", "O", and "R/C" are for CDASHIG. SDTMIG has "Req", "Exp", and "Perm". ADaMIG has "Req", "Cond", and "Perm". In other words, in this unstructured PDF container, certain semi-structured data can be asserted.
Therapeutic Area User Guides (TAUG) are largely unstructured. Even though TAUG publications may seem to follow a common document pattern, they often contain knowledge graphs, images, and data examples, albeit with varying degree of specificity. This is similar to digital photo files. Even though they are in a file format (JPEG, PNG, or GIF), the content is unstructured. A digital photo file needs to be processed to become an image for human cognition. Image recognition & analytic tools are needed to allow machine to learn and understand its meaning.

Typical composition of a CDISC publication that contains unstructured, semi-structured, and structured contents.
Controlled Terminology, on the other hand, has publication in PDF format rendered directly from raw data. The raw data is highly structured. NCI EVS maintains all codelist and terms in Protégé, an ontology tool. EVS extends Protégé with OWL, a web semantic layer.[1] Data serialization happens at each quarterly publication to produce formats available for download, such as CSV, Excel spreadsheet, and PDF. This structured data approach enables many scenarios of reusability. Define-XML, codelists & terms in implementation guides, and CDISC 360's biomedical concepts, just to name a few. Controlled Terminology reaps the benefit of repeatability by virtue of its highly structured nature. CDISC publishes Controlled Terminology four times per year, with a maximum of six packages each time. With this level of frequency and quantity, a repeatable process is a must.
Technology plays a significant role when working with various structuredness of data. An overall data architecture is a strategy that must be very well articulated. This impacts storage, analytics, accessibility, and discoverability. Computing evolves at rapid pace. Especially with cloud computing, it has created many choices in the marketplace for different kinds of data: RDBMS, graph database, document store, multi-model database. Long gone is the era where all data would go in to one single enterprise data store. Database-as-a-service has become a hot commodity, offering unprecedented flexibility, scalability, and modularity. Implementers today can choose to put their data in a right container for the right purpose.
In conclusion, today's CDISC products mostly fall into the semi-structured and unstructured categories. Data strategy with stakeholders about accessibility and usability should heavily influence the degree of structuredness in the kinds of data being managed, especially with novel contents. Decision makers need to factor in the strengths and weaknesses of each technology offering. Trade-offs may be inevitable, e.g., sacrifice end-to-end interoperability for a simplified data store? Prefer repeatability over schema flexibility? Immediate access or deferred availability? None of these questions have one answer for all the varying degrees of data structuredness.
[1] NCI Thesaurus Downloads: https://evs.nci.nih.gov/evs-download/thesaurus-downloads
Telephone (Chinese whispers or whisper down the lane, among other common name variations) is a children’s game in which the first child whispers a phrase to the next child, and so continues down the line. When it reaches the end, the last child reveals the phrase she heard to the entire group. The amusement comes witnessing how the original phrase becomes increasingly distorted between each pass, especially when it is played with an obscure phrase.
Variables are a common building block in all CDISC foundational standards. Their properties noticeably vary from one standard to another. For example, Variable Label, a descriptive text, is common across CDASH (data standards for collection), SEND/SDTM (for aggregation), and ADaM (for analysis). On the other hand, Role, which states how a variable functions in a given dataset, is a property unique to SDTM and Implementation Guides it supports. This distinction in variable properties is reasonable as each foundational standard addresses a specific purpose in the clinical data lifecycle. Nonetheless, variables must be accompanied by Definition. The purpose of Definition is, in a descriptive statement, to state the essential meaning of a variable in a precise and unambiguous manner.
Similarly, in a game of telephone, the more comprehensible a phrase to the players, the better chance it retains the original form at the end. However, an obscure phrase will very likely finish as gobbledygook.
It is not to say Definition is non-existent. Metadata tables published alongside the latest CDASH Model and Implementation Guide contain a column labeled Draft CDASH Definition for every variable. It is explained in section 3.5.1 of the CDASH Implementation Guide v2.0 (https://www.cdisc.org/standards/foundational/cdash/cdash-20#Bookmark18) that the CDASH team will harmonize its definitions with SDTM in the future.
Checking recent SDTM publications, the CDISC Notes column in the Implementation Guides (including Description in the Model) comes closest to Definition, though not a direct match. Unlike Variable Label, which has a character length limit due to regulatory data submission requirements, CDISC Notes has no such restrictions. Due to its free-form nature, CDISC Notes contain a variety of useful information: It may contain explanatory text, e.g., ‘Characterization of the duration of a biological process resulting in a particular finding.’ It may contain data examples, e.g., ‘Examples: "ng", "mg", or "mg/kg".’ It may contain data rules, e.g., ‘If MHTERM is modified to facilitate coding, then MHMODIFY will contain the modified text.’ It may contain usage rules, e.g., ‘When dosing of a treatment is recorded over multiple successive records, this variable is applicable only for the (chronologically) last record for the treatment.’ Extracting Definition from CDISC Notes will flush out other entangled properties and elucidate their purposes, such as rules, usages, and examples.
Data flow from one stage to another in a data lifecycle. Sources and targets formulate data lineage. Data rules may be added to describe manipulations such as data imputation, derivation, and transformation. It is a fundamental principle to not keep the same variable name whenever manipulation occurs between lifecycle stages that causes its meaning or any of its properties to change. Applying this principle to CDISC foundational standards, variable of the same name used between two lifecycle stages, e.g., from collection (CDASH) to aggregation (SEND/SDTM), ought to have the same essential meaning. The harmonization effort anticipated by the CDASH team embodies this principle.
Usability of data increases when they are dependable. Good definitions are key to achieving dependable data. People reasonably expect a high degree of permanence once definitions are established. Therefore, changes to definitions will need to be taken judiciously. This requires active governance, with an effective team of experts charged to establish and safeguard good definitions.
Other suggestions for good definitions are:
Specify valid values, but in a separate property to complement definitions. Valid values could mean codelists, value lists, external dictionaries. It is because data with different sets of valid values, more often than not, represent different (close, far, or unrelated) concepts.
Be type aware. A general concept may have specific usage with added constraints such as type. For example, U.S. ZIP code, belonging to the postal code concept, is a group of five or nine numbers that are used in conjunction with a postal address to assist the sorting of mail. The definitions may be incomplete without making clear that a U.S. ZIP code is numerical.
Use common lexicons. Referenceable knowledge eases comprehension. For example, epoch and randomization are words with specific connotation in the clinical context. It will be wise to leverage terms and definitions published in CDISC Glossary (https://www.cdisc.org/standards/semantics/glossary) to ensure their consistent and correct usage within foundational and therapeutic area standards.
Be conservative with the Model, be liberal with the Implementation Guides. Since all variable concepts in an Implementation Guide are created within the confines of the Model it references, variable definitions in the Model should be easily applied to domain-specific variables in an Implementation Guide, provided governance are robust for variable definitions in the Model.
It is important to note, good definitions shall not be embedded with example values in the text to avoid these situations:
Perpetual modifications. There have been more than isolated cases when people request example values be added, updated, or removed. These requests, even when it is done without altering a variable’s meaning, are modification nonetheless. As harmless as it may seem, the act resets the state of permanence. Low degree or lack of permanence indicates poor definitions.
Conflicting information. Valid values could be dependent on context. For example, different therapeutic areas may have slightly different requirements for a variable’s valid values. At CDISC, process has been established to document value subsets, conditional codelists, etc. Therefore, hard wiring example values to Definition will lead to confusions and sometimes conflicts with the actual valid values.
Chained definitions. It would be assuming that people understand the meaning of an example value added to Definition. When that isn’t the case, they will be required to refer another variable’s Definition or other sources, causing a chained effect. This chained effect is indicative of imprecise explanation in the first place.
Certain areas will likely be impacted, to a degree yet to be known, until some mandates about definitions are put in place. Formulating definitions are often more of an art than science, the practice of which could impact the speed of development. Additionally, domains, which are comprised of variables, are versioned in SDTM Implementation Guides. Variable definitions could impact the policy of when and how domains are up-versioned. Furthermore, concepts can have wide and narrow scopes (e.g., U.S. ZIP code is a subclass of the postal code concept; injection site is closely related to anatomical location, etc.), a CDISC ontology may emerge over time after achieving certain volume of well-defined variables. Last, but not least, some machine-readable mechanism will be a welcome replacement of today’s two-dimensional view for documenting all the intricacies about variable properties.
Enacting to allow definitions to be front and center during all standards development activities will require cross-team debate and consensus. It is undoubtedly going to disrupt current processes and norms. However, enormous benefits await. Not only will variables be disambiguated, variables and data will also no longer be interpreted dissimilarly due to poor or lack of definitions. With strong emphasis nowadays on linked data (i.e., published data with strong semantic backbone) and how cures could be unlocked by cross-domain data analyses, dependable data sources are a basic requirement to even begin tapping into its power.
In closing, let's imagine the contrasting results playing a game of telephone with these two versions of definitions for the variable Planned Arm Code (ARMCD). Unless all players have superior photographic memory, Game 1 will undoubtedly wind up far from the original. The succinct version for Game 2, in contrast, will likely survive the game with little to no distortions.
Game 1 | Game 2 |
|---|---|
| CDISC Notes as published in SDTMIG v3.2 | Definition as proposed by the Variable Definitions team |
| ARMCD is limited to 20 characters and does not have special character restrictions. The maximum length of ARMCD is longer than for other “short” variables to accommodate the kind of values that are likely to be needed for crossover trials. For example, if ARMCD values for a seven-period crossover were constructed using two-character abbreviations for each treatment and separating hyphens, the length of ARMCD values would be 20. | A short sequence of characters that represents the planned arm to which the subject was assigned. |
I have established, in this post, rationale for extracting and maintaining formal definitions for CDISC variables. At the same time, opportunities are here to also untangle all intricate variable properties from CDISC Notes or Description to bring normative information such as rules, usages, and other standards conformance details to light. Further, I have proposed variable definitions won’t be just another piece of information, but will serve an essential role in both governance and semantics. Lastly, I have recognized risks and challenges with this disruptive proposal, though those concerns are outweighed by many benefits. I hope to see your comments and debates on this topic.
Acknowledgements
I want to express my appreciation to my CDISC SHARE colleagues for their point of view on this topic which inspired me to author this blog entry: Dr. Sam Hume, Darcy Wold, Julie Chason, Dr. Lauren Becnel, and Frederik Malfait. Special thanks to Erin Muhlbradt, Ph.D. NCI Enterprise Vocabulary Services, for sharing her experience and insights in controlled terminology curation, as well as for proofreading this content.
Earlier this week, the curators released the metadata for SDTM v1.6 Final (https://www.cdisc.org/standards/foundational/sdtm) and SENDIG-DART v1.1 Final (https://www.cdisc.org/standards/foundational/send) to CDISC SHARE Exports (https://www.cdisc.org/members-only/share-exports). DART, an acronym for Developmental and Reproductive Toxicology, refers to study data typically found in embryo-fetal developmental toxicity studies. CDISC SHARE Exports is a part of the CDISC website where CDISC members can freely access static metadata output from SHARE. Please contact our Membership team for assistance with access (https://www.cdisc.org/contact).
Released together with the aforementioned metadata is Diff report. Diff, a shorthand for differences, is a computing term whose main purpose is to detect and display the alterations between two files. Changes made to SDTM v1.6 from its predecessor such as new variables and updated properties are detailed in the report. Another Diff report is comparing v1.1 to v1.0 of SENDIG-DART. SENDIG-DART v1.0 was published in August, 2016 with a Provisional status. This second Diff is a useful tool to aid patching or updating to the Final version.
Curation for SENDIG-DART's metadata was particularly challenging; the SENDIG-DART is intended to be used in close concert with the SENDIG v3.1. The SENDIG-DART supplements the SENDIG with seven (7) new domains, spanning special purpose, findings, and trial design classes. Majority of the changes, however, lies in Section 7 - Changes to Existing Domains (https://www.cdisc.org/system/files/members/standard/foundational/send/SENDIG%20DART%20v1.1.pdf#page=38) and Appendix C - Repro Phase Day Timing Variables (https://www.cdisc.org/system/files/members/standard/foundational/send/SENDIG%20DART%20v1.1.pdf#page=45). These sections document modifications to sixteen (16) other domains, of varying degrees, for DART studies. The modifications are written primarily for human consumption, which poses the challenge. Extra time was necessary to carefully curate the full domain specification for those affected domains. Curation mostly entailed interpreting textual information in multiple subsections (e.g., “After RFENDTC, before RFXENDTC”, “BWBLFL variable is Permissible for DART studies”, etc.), then stitching them back to domain specification tables in SENDIG v3.1.
To ensure accurate interpretation and complete coverage, the curators arranged a special quality review cycle with the SEND Leadership Team. During which, not only a few corrections were advised, but a last-minute update to the SENDIG-DART document was also warranted. The entire curation process took about three and half months.
The metadata posted onto CDISC SHARE Exports would be impossible without the eyes and expertise by all parties involved. The end result is worthwhile as fully vetted metadata (Excel and Define-XML v2.0 for SENDIG-DART) are accessible to all CDISC members. They are a significant time saver to otherwise a tedious process to be undertaken by each sponsor company.
On a different note, it is opportune to summarize other metadata-related work completed in 2017. The SHARE team conducted a public input for both SHARE 2.0 Model (Q3) and SHARE 2.0 API (Q4). They are important work to lay a strong foundation for delivery CDISC metadata in a machine-readable format. They are the backbone for structured metadata, tools, and automation so that CDISC will be able to make new metadata available much more rapidly. We are starting to reap benefits from several homegrown tools: 1) CRF Maker that uses metadata to automate CRF annotations for use in Therapeutic Area User Guides; 2) QRS Maker that generates questionnaire dataset with both question and result metadata; 3) Spec Grabber that swipes properly structured dataset specification tables in CDISC WIKI and produces machine-readable metadata. This is an area we will certainly do a lot more in 2018.
For coming attractions, there are a few development work this community may anticipate during Q1 and Q2 next year. Sample metadata will be loaded into our API specification development platform, hosted on Swaggerhub (https://app.swaggerhub.com/apis/CDISC1/share-2.0). This will greatly enhance the API testing experience, especially for prospective users to experiment with RESTful API. A SHARE 2.0 soft launch, both Model and API, is projected for late Q2 with a good set of popular versioned standard included. If time permits, HL7 FHIR mappings to CDASH and SDTM, limited to concepts covered in CDISC’s Diabetes Therapeutic User Guide, could be in scope. More details about the soft launch will be shared once they become available.
Lastly, thank you for your partnership in 2017. We truly believe CDISC members drive global standards.
May you have a restful holiday and a rewarding new year to come.
“Is SHARE available now?”
“How do I access eSHARE?”
“What kind of metadata is available in SHARE now?”
“What can I do with SHARE metadata?”
“What is new in SHARE for 2016?”
This is a sample of frequently asked questions at the SHARE booth during the Interchange; the SHARE and eSource demonstration booths were conveniently situated outside the conference break room, where attendees enjoyed their meals and refreshments. With guaranteed foot traffic, the location maximized our opportunity to socialize SHARE’s values and benefits.
We set up a TV monitor at the SHARE booth, looping a presentation slide deck that details what the team accomplished in 2015 and planned for 2016. To the right was the SHARE poster set on an easel. The CDISC model on the poster facilitated many conversations. It diagrams the lay of the land of all CDISC products in a simple way. It depicts product relationships and identifies SHARE deliverables in a single bird’s-eye view.
We also conducted a number of unscripted demonstrations. They ranged from signing onto eSHARE, reviewing different types of metadata offered, looking under the hood and the inside of SHARE, and introducing the SHARE WIKI. The curious audience often charmed by Semantics Manager, the front-end interface of SHARE, especially how it intuitively displays the inter-connection of CDASH, SDTM, ADaM, Controlled Terminology, BRIDG, and ISO 21090.
Many people were very interested in our biomedical concept development. They believed metadata such as protocol elements (e.g., objectives, endpoints) and value-level metadata (e.g., variables, codelist subsets, and value lists) would help streamline processes and enable software automation. From conversations, late stage data conversion and retrospective Define.xml creation are still running rampant in the industry. SHARE can certainly do more to influence a paradigm shift so people will no longer need to tackle information chaos with “black box” operations using archaic technology.
In closing, please watch our eSHARE Gold Member Rollout webinar recorded on 2015-09-10 from the CDISC webinar archive. It gives a thorough overview of eSHARE. Furthermore, this short iSHARE video is first of the mini-series designed to show how the metadata repository manages our standards.
The Standards Review Council (SRC) recently reviewed the SDTM conformance rules ("Rules") produced by the SDTMV. After having painstakingly combed through the SDTM v1.4 and SDTMIG v3.2, the team identified 400+ rule candidates. At the time of this blog post, the SRC is working with the sub-team to address some reviewer comments before making the package available for Public Review. As you can preview here, the construct is not very different from those published by the FDA SDTM Validation Rules and OpenCDISC Community: Rules have identifier, context, rule description in some pre-specified lexicons, condition, and citation of the rule's source.
As a Metadata Curator, I need to ask myself what the Rules mean to SHARE, as metadata. The text and description are, by definition, not metadata. Extra steps are needed to tease out the metadata. I thought to first illustrate a typical rule construct, or a model, shown here:

Furthermore, I formulated these objectives to help me devise solutions (my philosophy to innovate: first understand the what's before bother with the how's):
- A rule may not only limit to so-called validation, but wide varieties of constraints such as referential integrity, data ranges, data derivations, inter-dependencies, etc.
- A rule may be direct, which are used to express a piece of data in some data elements, a data element in some classes, or some classes within a model.
- Conversely, a rule may be descriptive, whose description or condition is not directly related to the data, data elements, classes, or models.
- Rule metadata may be platform independent and vendor neutral.
- Rule metadata may be machine-computable, and at the same time may be complemented by natural language. This and Objective #4 together mean the rule metadata may not be machine-executable.
- Rule metadata may allow third party players such as vendors, pharmaceutical companies, regulatory agencies, etc., to consume a common set of constraints and enable them to do what they want with it.
- Rule metadata may disambiguate any undesirable ambiguity often found in natural language used to describe rules.
Additionally, I self-imposed some scoping limitations, i.e., a list of "won't do's" to keep implementation simple so this can be completed within a reasonable amount of time:
- Shall not invent a pseudocode mechanism. By the same token, shall not invent new grammars and expressions.
- Shall not invent a software.
- Shall not need to cover all Rules, recognizing not everything will fit perfectly.
Having done some research along with inputs from volunteers and peers, two choices were available. They are both open standards and fit my objectives:
- HL7 GELLO, most current version Release 2
- Object Management Group (OMG) Object Constraint Language (OCL), most current version 2.4
At first, I found HL7 GELLO fascinating, supporting a huge range of medical and healthcare data. After all, it is designed to be a clinical decision support system. That said, having required to understand HL7 RIM and specialized toolset, it will be very difficult to find a sustainable workforce to develop and maintain using the GELLO framework.
A little bit more research revealed GELLO is in fact created based on OMG OCL. Here are a few characteristics that resonate with me and my Objectives:
- It is aligned with both Unified Modeling Language (UML) and Meta Object Facility (MOF). It is often described as partner standard to UML. It is fair to say you can't have UML without OCL.
- It is object-oriented, meaning constraints are placed directly onto objects and classes in a model.
- It has inheritance, therefore model expansions by instantiating new objects from classes will carry over existing constraints.
- Context matters. An OCL must declare context where the constraints apply. This is an essential element to achieve disambiguation. For example, context can be an object, a class, a set, a tuple (such as value list), an association, etc.
- It is assertion based, most noticeable by the invariant constraint type. Invariants are conditions that must be true. This coincide with the SDTM Validation Sub-Team's approach, which emphasizes on the "positives."
- It supports both pre- and post-conditions. They will be useful to implement conditions information in Rules.
- It is supported by a number of commercial off-the-shelf (e.g., Enterprise Architect, MagicDraw) and open-source software (e.g., Eclipse).
This diagram nicely depicts the information architecture we use and how the CDISC product family stack up in terms of overall model framework.

Those said and illustrated, OMG OCL represents a no-brainer choice to me. UML, hence OCL, is the next logic step to further with (and, complete) the architectural blueprint.
I have only recently begun studying the OCL specifications to solidify my thinking. I hope the little work I attempted helps demonstrate this proposal. Below is a subset of the SDTM Findings class drawn using Enterprise Architect:

I added a couple of OCL to --TESTCD:
- --TESTCD, being a topic variable, cannot be null.
- --TESTCD has length less than equal to 8.
- --TESTCD has a data pattern requirement, contains only uppercase letters, numbers, and underscores, with the first character must be a uppercase letter.
Their OCL expressions are as follows:

Imagine we will be able to run test data through the whole series of OCL as an exercise to validate the correctness of the constraints. This will enable us to run example data to test their validity prior to including them in Implementation Guides or User Guides. As a matter of fact, they are not a far-fetched ideas. This Youtube video posted by a third party modeling tool, called MagicDraw, adequately demonstrates the power of test automation using OCL functionality. At 6:00, the video shows how easy it is to validate an OCL using some XML data: prepare an XML file guaranteed to trigger a constraint violation, run it against the rules in a compiled Java code and the auto-generated schema file. Pretty nifty.
The vision of this proposal:
- CDISC will treat and maintain the SDTM as a true data model.
- Model constraints such as rules, derivations, and domain inter-dependencies will be normative and be part of each point release.
- SDTMIG will be drastically less voluminous. Much of the text aimed to explain implementation will be replaced by rules and constraint metadata alike.
- Additional SHARE automation can be had through meta-metadata and its constraints.
In conclusion, SHARE influences a certain discipline and conduct toward the standards development process. Engineering SDTM with an UML model and refitting validation rules using OCL are not only logical, but essential to lead the industry with technical innovation. Furthermore, this will address a lot of model and implementation ambiguities currently exist. Lastly, I'd like to make a call for volunteers to further implement this proposal. Perhaps, a proof of concept project to create a testbed to apply model constraints and rules metadata toward submission data validation and other uses.
Earlier last week, my colleague , in which he proposed the idea of "embedded keys" at 01:45 How would James, the fictitious forms designer, do to build a data capture form with these embedded keys?
Let's use the same vital signs example. First, we have a few widgets for the physical layer, i.e., variables. Together they form a wireframe of a vital signs data collection module. Each variable has a NCI c-code, a name, and a definition:

Next, we have several widgets for the medical concepts surrounding blood pressure. Similar to the variable widgets, they also have a NCI c-code, a name and a definition.:

In the above diagram, motice how the c-code for Blood Pressure and Vital Signs begins with CUI, or Concept Unique Identifier. The fact is, in the NCI Metathesaurus, these concepts come pre-assembled with relationships, such that:

The last set of widgets are the controlled terminology.

We have all the widgets, allowing us to assemble a well-defined capture form with all necessary "embedded keys".

In conclusion, the "embedded keys" will not only serve as the conduit to the healthcare link side of interoperability, they can also be used to tie conceptual ideas (knowledge) to the physical implementations (SDTM). This way, it doesn't really matter the verbiages used on a CRF because the c-codes uphold the underlying semantics.

References:
- CDISC Variable Terminology on NCI Thesaurus: http://ncit.nci.nih.gov/ncitbrowser/ajax?action=values&vsd_uri=http://evs.nci.nih.gov/valueset/C83187
- NCI Metathesaurus: http://ncimeta.nci.nih.gov/ncimbrowser/
- Blood Pressure concept and relationships on NCI Metathesaurus: http://ncimeta.nci.nih.gov/ncimbrowser/pages/concept_details.jsf?dictionary=NCI%20MetaThesaurus&code=C0005823&type=relationship
Introduction
CDISC Controlled Terminology (CT) maintains a codelist of units of measurement (codelist code C71620, short name UNIT). It is used to represent values for unit variables in various domains, such as demographics (AGEU), concomitant medications (CMDOSU), lab (LBORRESU, LBSTRESU), vital signs (VSORRESU, VSSTRESU). Note: AGEU is a codelist subset of the UNIT superset.
Indiana University School of Medicine's Regenstrief Institute develops the Unified Code for Units of Measure (UCUM). It is a code system of units intended to be unambiguous to both human and machine. It has many applications in life sciences, such as EHR, and, EDI and HL7 electronic messaging. Logical Observation Identifiers Names and Codes (LOINC) is another code system that incorporates UCUM.
Even though many terms are identical between CDISC and UCUM, there are differences. For example, millimeter of mercury, a unit commonly used to measure blood pressure, is mmHg in CDISC, while mm[Hg] in UCUM. Here are a few examples showing differing values:
| Table 1: CDISC CT vs. UCUM | ||
| Long Label | CDISC CT | UCUM |
|---|---|---|
| Cells per Microliter | cells/uL | {Cells}/uL |
| Hour | HOURS | h |
| Joule | Joule | J |
| Millimeter of Mercury | mmHg | mm[Hg] |
| Millisecond | msec | ms |
| Pound | LB | [lb_av] |
| Tablet Dosing Unit | TABLET | {tbl} |
Therefore, a mapping between the two codelists is helpful for any two heterogeneous systems to be interoperable and be successful at exchanging data.
NCI EVS Resources
CDISC and NCI EVS have long been partners at curating and registering CDISC controlled terminologies in the NCI Thesaurus (NCIt), hence the NCI Metathesaurus (NCIm). As a matter of fact, a careful examination into NCIm reveals the relationship between CDISC and UCUM exists. A search of the term millimeter of mercury shows the evidence (source: http://1.usa.gov/1zoRA96):

At this point, we gather these about the NCI EVS:
- All CDISC CT can be retrieved from the NCIt browser
- NCIt contains biomedical knowledge from multiple sources, e.g., CDISC, UCUM, SNOMED, etc.
- Relationships between sources are maintained, where applicable
Thesaurus OWL/RDF
Despite being off to a good start, manual lookup via the NCIt browser would be too tedious to be useful. Upon further research, NCI Center for Biomedical Informatics and Information Technology (CBIIT) publishes the NCIt in OWL/RDF format in a regular basis.
With an OWL/RDF file at our disposal, SPARQL is the tool to do some graph-based data analyses.
The following is a snippet from the Thesaurus OWL/RDF file, showing how it represents metadata for the term millimeter of mercury:
Millimeter of Mercury from Thesaurus.OWL
<!-- http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl#Millimeter_of_Mercury -->
<owl:Class rdf:about="#C49670">
<rdfs:label rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Millimeter of Mercury</rdfs:label>
<rdfs:subClassOf rdf:resource="#C67332"/>
<P97 rdf:parseType="Literal"><ncicp:ComplexDefinition><ncicp:def-definition>A non-SI unit of pressure equal to 133,332 Pa or 1.316E10-3 standard atmosphere. Use of this unit is generally deprecated by ISO and IUPAC.</ncicp:def-definition><ncicp:def-source>NCI</ncicp:def-source></ncicp:ComplexDefinition></P97>
<P325 rdf:parseType="Literal"><ncicp:ComplexDefinition><ncicp:def-definition>A unit of pressure equal to 0.001316 atmosphere and equal to the pressure indicated by one millimeter rise of mercury in a barometer at the Earth's surface. (NCI)</ncicp:def-definition><ncicp:def-source>CDISC</ncicp:def-source></ncicp:ComplexDefinition></P325>
<P90 rdf:parseType="Literal"><ncicp:ComplexTerm><ncicp:term-name>mm[Hg]</ncicp:term-name><ncicp:term-group>AB</ncicp:term-group><ncicp:term-source>UCUM</ncicp:term-source></ncicp:ComplexTerm></P90>
<code rdf:datatype="http://www.w3.org/2001/XMLSchema#string">C49670</code>
<P108 rdf:datatype="http://www.w3.org/2001/XMLSchema#string">Millimeter of Mercury</P108>
<A8 rdf:resource="http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl#C71620"/>
</owl:Class>
To de-reference the pseudo-properties P90 (Synonym with Source Data) and P108 (Preferred Name) above:
An explanation for the above OWL snippet:
- Line #3 is the beginning of the owl:Class C49670, which, by no accident, is the c-code for millimeter of mercury we are accustomed to seeing on the CDISC CT spreadsheet.
- On line #11, it shows C49670 is associated to another class C71620, which is the UNIT codelist itself.
- On line #9, it contains the c-code as a property.
- On line #10, it contains the NCI preferred name of C49670.
- On line #8, it contains the UCUM mapping. Note that the value AB in the XML tag ncicp:term-group signifies the entry is about unit symbols used by UCUM. Other values may appear, but do not relate to this demonstration.
- Lines #6-7 contain definitions of the class.
- Lines #15-41 contain definitions of the pseudo-properties P90 and P108 for easy reference. There are many other pseudo-objects in the Thesaurus OWL/RDF files.
With the above sample depicting the model, the following is a SPARQL query for obtaining a list objects having a UCUM mapping:
SPARQL for Extracting UCUM Mappings
PREFIX nci: <http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl#>
SELECT ?conceptCode ?preferredName (STRAFTER(STRBEFORE(STR(?synonym), "</ncicp:term-name>"), "<ncicp:term-name>") as ?ucum)
FROM <http://ncicb.nci.nih.gov/xml/owl/EVS/Thesaurus.owl>
WHERE {
?class a owl:Class ;
nci:code ?conceptCode ;
nci:P108 ?preferredName ;
nci:P90 ?synonym .
FILTER(STRAFTER(STRBEFORE(STR(?synonym), "</ncicp:term-source>"), "<ncicp:term-source>") = "UCUM")
FILTER(STRAFTER(STRBEFORE(STR(?synonym), "</ncicp:term-group>"), "<ncicp:term-group>") = "AB")
}
A sample output matching the terms shown in Table 1 above:
| Table 2: Partial results from extracting metadata in Thesaurus OWL/RDF using SPARQL | ||
| conceptCode | preferredName | ucum |
|---|---|---|
| C67242 | Cells per Microliter | {Cells}/uL |
| C25529 | Hour | h |
| C42548 | Joule | J |
| C49670 | Millimeter of Mercury | mm[Hg] |
| C41140 | Millisecond | ms |
| C48531 | Pound | [lb_av] |
| C48542 | Tablet Dosing Unit | {tbl} |
CDISC CT OWL/RDF
Incidentally, all CDISC CT packages are also available in OWL/RDF. The goal is to reduce the UCUM query above to only the entries found on the UNIT (C71620) codelist. Continuing with the flow, this is a snippet from the CDISC CT OWL/RDF for the same term, millimeter of mercury:
Millimeter of Mercury from sdtm-terminology.owl
<CodeList OID="CL.C71620.UNIT" Name="Unit" DataType="text" nciodm:ExtCodeID="C71620" nciodm:CodeListExtensible="Yes">
<Description>
<TranslatedText xml:lang="en">Terminology codelist used for units within CDISC.</TranslatedText>
</Description>
<EnumeratedItem CodedValue="mmHg" nciodm:ExtCodeID="C49670">
<nciodm:CDISCSynonym>Millimeter of Mercury</nciodm:CDISCSynonym>
<nciodm:CDISCDefinition>A unit of pressure equal to 0.001316 atmosphere and equal to the pressure indicated by one millimeter rise of mercury in a barometer at the Earth's surface. (NCI)</nciodm:CDISCDefinition>
<nciodm:PreferredTerm>Millimeter of Mercury</nciodm:PreferredTerm>
</EnumeratedItem>
<nciodm:CDISCSubmissionValue>UNIT</nciodm:CDISCSubmissionValue>
<nciodm:CDISCSynonym>Unit</nciodm:CDISCSynonym>
<nciodm:PreferredTerm>CDISC SDTM Unit of Measure Terminology</nciodm:PreferredTerm>
</CodeList>
Unlike the esoteric nature in the Thesaurus OWL/RDF, the CDISC CT one is very straightforward and readable. With that, here is a SPARQL query to extract information such as submission values and their c-code from the UNIT codelist:
SPARQL for Extracting UCUM Mappings
PREFIX mms: <http://rdf.cdisc.org/mms#>
PREFIX cts: <http://rdf.cdisc.org/ct/schema#>
SELECT ?conceptCode ?cdiscSubmissionVal
FROM <http://rdf.cdisc.org/ct/schema>
FROM <http://rdf.cdisc.org/mms>
FROM <http://rdf.cdisc.org/sdtm-terminology>
WHERE {
?pv a mms:PermissibleValue ;
cts:nciCode ?conceptCode ;
cts:cdiscSubmissionValue ?cdiscSubmissionVal ;
mms:inValueDomain ?clCcode .
{
?clCcode cts:codelistName ?clName ;
cts:nciCode "C71620" ;
}
}
A sample output matching the terms shown in Tables 1 and 2 above:
| Table 3: Partial results from extracting metadata in CDISC OWL/RDF using SPARQL | |
| conceptCode | cdiscSubmissionVal |
|---|---|
| C67242 | cells/uL |
| C25529 | HOURS |
| C42548 | Joule |
| C48531 | LB |
| C49670 | mmHg |
| C41140 | msec |
| C48542 | TABLET |
Final Query and Output
The two result sets can be linked via the individual term's c-code. Therefore, the final query is a combination of the two SPARQL queries above, with a slight adjustment to make the nested queries work efficiently. It yields 143 mappings for 130 unique terms.
- cdisc_ct_ucum.rq - Final SPARQL text that extract UCUM information from Thesaurus and subset it to the UNIT codelist in CDISC CT
- cdisc_ct_ucum.txt - Result set in tab-delimited format
Conclusion
NCI EVS actively maintains a rich repository of terminology and biomedical ontology. Their OWL/RDF offering enables scalable IT solutions to search, link, and combine intricate biomedical concepts. This demonstration illustrates one semantic web technology application. SPARQL made analyzing over 2,160,000 triples (2,100,000 from Thesaurus, 60,000 from CDISC CT for SDTM) with ease. The more UCUM entries curated by NCI EVS, the more mappings will become available.
End Notes
- SPARQL as specified by W3C: http://www.w3.org/2009/sparql/wiki/Main_Page
- All SPARQL queries and OWL/RDF files were processed using TopQuadrant TopBraid Composer FE Version 4.4.0.
- These file versions are used in this demonstration: NCI Thesaurus 14.10d; and, CDISC CT 2014-09-26
- URL to download NCI Thesaurus OWL/RDF: http://cbiit.nci.nih.gov/evs-download/thesaurus-downloads
- URL to download CDISC CT OWL/RDF for SDTM: http://evs.nci.nih.gov/ftp1/CDISC/SDTM/SDTM%20Terminology.OWL.zip
Edits: 2015-01-10 Added another offending character, NO-BREAK SPACE
My recent focus has been loading additional content into SHARE to enrich our offerings, such as TAUG and draft SDTM publications published in 4Q2014. I spent a lot of time having to clean up the obstreperous characters in my Word document sources (i.e., the documents used to render the PDF). I feel compelled to write this short blog entry, hoping it will give you a jump start if you happen to perform similar tasks.
The most significant offenders are the so-called smart quotes. Microsoft Word, as a default, auto-formats straight to curly quotes, meaning it automatically corrects every time you hit the single- or double-quote keys. So, what's wrong with the smart quotes and why am I mucking around with them? First of all, they are not consistently used by our volunteer authors since user can disable the AutoCorrect feature. Second, these character are not ASCII and can only understood by software applications that supports UTF. Until our industry is more acquainted with XML technologies, forcing UTF would introduce unnecessary burden of data transport incompatibilities.
Sidebar
SOA Semantics Manager is a web-based application and supports UTF. For SHARE, we use the default configuration option for character set displays, which is UTF-8. The backend database uses UTF for character encoding.
Hyphens. Apart from the one on the keyboard, four other flavors have been detected, which are not part of ASCII.
Perhaps, the worst kind of obstreperous characters are those non-printerables. You know they are there, but you can't see it. They are hard to detect like household parasites, tagging along in copy-paste buffer.
Below is a table containing a list known offending UTF characters, with replacement values we perform in SHARE.
| Character Image | Unicode Name (Code Point) | Replacement ASCII Character (Decimal) | Remarks |
|---|---|---|---|
 | LEFT SINGLE QUOTATION MARK (U+2018) | ' (39) |
|
 | RIGHT SINGLE QUOTATION MARK (U+2019) | ' (39) |
|
 | LEFT DOUBLE QUOTATION MARK (U+201D) | " (34) |
|
 | RIGHT DOUBLE QUOTATION MARK (U+201D) | " (34) |
|
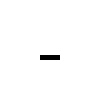 | NON-BREAKING HYPHEN (U+2011) | - (45) | |
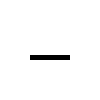 | FIGURE DASH (U+2012) | - (45) |
|
 | EN DASH (U+2013) | - (45) |
|
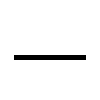 | EM DASH (U+2014) | - (45) |
|
 | HORIZONTAL ELLIPSIS (U+2026) | ... (46, 3 times) |
|
 | ZERO WIDTH SPACE (U+200B) | null (0) |
An example with text:
|
 | NO-BREAK SPACE (U+00A0) | whitespace (32) |
An example with text:
|




Image credit: FileFormat.info
Lastly, here is a snippet of Perl code that implements the above table:
Transform Unicode
sub transformUnicode{
my @input = @_;
for (@input){
s/\x{2018}/'/g; s/\x{2019}/'/g; # left and right curly single-quote
s/\x{201c}/"/g; s/\x{201d}/"/g; # left and right curly double-quote
# all kinds of hyphens/dashes
s/\x{2011}/-/g; # Non-breaking hyphen
s/\x{2012}/-/g; # Figure dash
s/\x{2013}/-/g; # En dash
s/\x{2014}/-/g; # Em dash
s/\x{2026}/.../g; # Horizontal ellipse
# all kinds of spaces
s/\x{00a0}/ /g; # No-break space, a.k.a. Microsoft Word's nonbreaking break
s/\x{200b}//g; # Zero width space, a.k.a. Microsoft Word's optional break
}
return wantarray ? @input : $input[0];
}
For reasons such as reporting, analyses, common conventions, one can be motivated to represent a value content in multiple ways to serve their functional purposes. One must not, though, neglect to preserve each value's semantic meaning in the process of doing it. I will describe how we accomplish this goal in the SHARE MDR in this blog entry.
Let's start with an anatomy of metadata: A CDISC SDTM domain or ADaM dataset includes variables. A variable is either represented by a CDISC Controlled Terminology codelist or by a value format. For example, ADaM ADAE (adverse event analysis dataset) includes AESEV (Severity/Intensity) variable, which is represented by the AESEV (CDISC SDTM Severity Intensity Scale for Adverse Event Terminology) codelist.[1] This AESEV codelist has 3 permissible values, MILD, MODERATE, SEVERE, with specific meaning.[2]
This ISO 11179 metamodel region[3] can be used to generalize these metadata components:

Therefore, after annotating the above diagram with the AESEV example, we have:

ADAE.AESEV has a numerical sibling, ADAE.AESEVN. Its CDISC Notes read "Code AE.AESEV to numeric," followed by "Low intensity should correspond to low value." Most important, its representation is "1, 2, 3". We can deduce using that information to say 1 corresponds to MILD, 2 to MODERATE, and 3 to SEVERE. In other words, 1 and MILD share the same value meaning, such that:

The remaining steps to do in the MDR are as follows:
- Proceed with building the remaining two permissible values
- Ensure each permissible value is part of the same concept
- Associate them to their respective codelists
- Assign the variables these codelists represent
The picture after stitching all these steps looks like this:

Notice, to the right on the picture, how the AESEV (C66769) codelist is associated to variables from 2 foundational standards? Therefore, at the physical layer, there are no ambiguations these variables in 2 datasets share the same semantic content, underscoring reusability.
In conclusion, ISO 11179 Part 3's concept region outlines a relationship that unifies concepts, terms, codelists, and semantics in a MDR. Though, in CDISC standards, it is rare to see multiple value domain sets having the same value meanings. This scenario is much more likely to exist in a pharma company. The ISO 3166 country code is a good example, which has multiple value domains. E.g., the long name for site management using a CTMS, the alpha-3 code for submission data specifically SDTM.DM.COUNTRY, etc.
References
[1] Analysis Data Model (ADaM) Data Structure for Adverse Event Analysis. Section 4.1.8, pg 18. http://www.cdisc.org/system/files/members/standard/adam_ae_final_v1.pdf
[2] Value set for CDISC SDTM Severity Intensity Scale for Adverse Event Terminology. NCI Thesaurus. National Cancer Institute. http://ncit.nci.nih.gov/ncitbrowser/ajax?action=values&vsd_uri=http://evs.nci.nih.gov/valueset/C66769
[3] ISO/IEC11179-3 Information technology — Metadata registries (MDR) — Part 3: Registry metamodel and basic attributes. Third edition 2013-02-15. http://metadata-standards.org/11179/index.html
Taking a cross-country flight from California to Dulles allows me amble time to write a blog entry. What else would I do when there is no Skymall Magazine to entertain me? Besides, Pittsburgh is getting crushed by the Jets. That is at least in the first quarter, anyway.
So, RCMap is the topic of this blog. The best way to give you a preview is to export the relevant components as web pages. It is about the low-density lipoprotein lab test, or LDL. I could not get tooltips to show. Please take a mental note that the tool does show extra metadata as tooltips when I hover on the bubbles, especially on those Controlled Terminology. It looks like this:

I recently studied the SHARE metadata display templates (MDT) attached to two Therapeutic Area User Guides (TAUG), Asthma and Diabetes. My first reaction, "Oh no, more spreadsheets." I blogged here explaining how loading metadata from spreadsheet wasn't as easy as it seemed. Creating research concepts in spreadsheet format adds another new dimension of complexities. But, before we go deep into this blog topic, first please know I recognize MDTs in the aforementioned TAUGs are prototypes and acknowledge a great deal of effort was put in to laying a foundation for concept creations. Second, it helps to describe the methodology as I understood it: These templates use multiple data element concepts (DEC) to describe a group of related research concepts. Each DEC consists of BRIDG class and attribute, ISO 12090 data type, SDTM variable, and CDISC Controlled Terminology. A single research concept can be created by instantiating from an MDT, subtracting irrelevant DECs, and constraining with additional controlled terms.
Challenges, as I see, are multi-folds. First, friendliness. These metadata displays were probably never meant to be user-friendly as they are very heavy on metadata, without a Layman translation such as descriptions. They are also not very machine-friendly because worksheet tabs, merged cells, color coding, text stylization mean hidden metadata that require additional extrapolations.
Second, consistency. The free form nature of spreadsheet is not the only contributing factor. There is also the cross-referencing to Controlled Terminology. And, I mean a lot of it. As I mentioned above, this research concept creation methodology hinges heavily on the use of controlled terms to constrain a template. You can imagine it requires a lot of looking up to Controlled Terminology (spreadsheets likely), followed by copying and pasting. Further, new therapeutic areas (TA) often require new codelists and terms. With many concurrent TAUG developments, communication is a definite challenge across TA teams to define new items collaboratively and consistently.
Third, communication, which is tightly related to consistency. We want to reap the benefit of reusability from well-crafted MDTs and research concepts. Think about labs and how frequently they are used in safety and primary endpoints. Reuse means time saving, which equates to efficiency. Moreover, a research concept can be a composite of several related research concepts. Related disease area such as asthma and COPD in pulmonary function disorder can be developed in parallel. These advantages would be difficult to achieve by standalone spreadsheets.
Fourth, sustainability. Granted, it is more of an issue on process and resources (i.e., operationalizing the methodology) than the methodology per se. It is nonetheless a growing challenge with an increasing rate of new TAs commencing. The toolset for creating research concept needs to be easy to use, quick to learn, and without a heavy baggage of inherent spreadsheet annoyances.
All of the above reasons motivated me to explore options, thus RCMap. It is a methodology based on visualization and knowledge organization. As you may notice from the preview of LDL test above, I used CmapTools as the conduit to demonstrate the idea. CmapTools is a visual tool. Users express ideas and concepts as bubbles (parts) and lines (relationships between any two parts). It has a good search functionality. It uses folder structure for organization. Drag and drop to reuse ideas and concepts is a bliss. And, it is a familiar software to the metadata developers and is in free beta offering.
To make RCMap useful to concept modelers and metadata developers, I had to do some preparation work. First, I exported Controlled Terminology codelists and terms from SHARE and import them as concepts. By making them concepts, users will be able to search the terms they need, either by name or by any of the Controlled Terminology attributes. They will be able to review the results, then drag and drop a match into the research concept they are creating. Likewise, I made SDTM variables available as reference objects. This way, metadata developers will be able to easily associate a DEC with appropriate SDTM variables, say LBTEST and LBTESTCD for Lab Test. The result is a tight binding among controlled term, SDTM variable, and DEC. It takes the ambiguity and guessing game away, which many of CDISC implementers want.
MDTs are patterns in RCMap. Patterns that contains visually appealing predefined DECs, relationships, and controlled terms. They are readily available for reuse. It will not choke at complex research concepts that require intricate linkages to related concepts because they are simply another set of bubble and line, where the target concept is just a click away. I can see the concept modelers to use a folder like structure to organize related patterns into a hierarchical arrangement. Here is a sample to arrange research concepts, SDTM variables, and controlled terms:



Some Excel manipulations of the XML data exported from RCMap allows me to create a metadata display that mimics the ones bundled in the two TAUGs. Here is a sample for the LDL, Direct lab test research concept, where you can see both the SDTM variables and controlled terms.

It is suffice to say automation is not the focus here. I believe enough research concepts need to exist before automation is attainable. Only when there are sufficient patterns, meta-patterns can be ascertained.
At the time of this blog entry, one of the few remaining hurdles is to encapsulate BRIDG metadata into RCMap. I hope to discuss options with the metadata developers, such as using similar approach to binding SDTM variables to DEC, i.e., binding BRIDG class and attribute to DEC. Another hurdle is identifying role of SHARE in relation to RCMap. It is not a matter of technology because CmapTools has an excellent XML technology backbone. Rather, it is the curation and governance process.
Well, my flight is at the approaching phase to Dulles. I look forward to the 12th Annual CDISC International Interchanage.
We imported the SDTM metadata spreadsheet on the CDISC website to formulate the baseline content. During our recent quality sweep, we realized some relationships didn't look right and some were missing. Take Findings About, for example. Findings About was shown as a class at the same level of the 3 general observations classes. Further, domain FA was a member of the Findings class (see Before relationship graph on the right). Information about these relationships was not included in the original SDTM metadata spreadsheet, nor were they explicit in the standard. We approached the SDS Leadership Team and obtained the authoritative information about their relationships (see After relationship graph). The revised metadata now reflects the true intention of the model, which the 2-dimensional metadata spreadsheet didn't address.
Findings About: Before Changes

Findings About: After Changes to Correct Relationships

The DOMAIN variable in each SDTMIG domain demonstrates another good use of relationships. In SDTM, DOMAIN gets a constant value, which depends on the domain it belongs. For example, the value of AE.DOMAIN is "AE". This is quite different from AE.DOMAIN being represented by a character VD (see Before relationship graph on the right). We decided we ought to be expressive, and most importantly, take advantage of the CDISC Controlled Terminology assets that already exist in the MDR. After the revision, AE.DOMAIN has a much richer set of metadata (see After relationship graph) -- The variable now has a VD representation that contains only 1 domain value (DV) of "AE", of which implements the NCI EVS concept code of C49562, of which subsets from the CDISC SDTM Submission Domain Abbreviation Terminology codelist. That's clarity.
AE.DOMAIN: Before Changes

AE.DOMAIN: After Changes to Add Richness in Metadata

Lastly, I leave you this (in reference to SHARE). Your feedbacks are always welcome.
